Multiproceso con ArcGIS - Análisis de trama
por Neeraj Rajasekar
Con el crecimiento de los tamaños de datos de ráster, los tiempos de procesamiento para el análisis son cada vez más largos. Sin embargo, al emplear conceptos de computación en paralelo, podemos mejorar el rendimiento y la escalabilidad de los flujos de trabajo con las herramientas de Spatial Analyst. En este blog, identificaremos escenarios donde el módulo de multiprocesamiento Python (Python.org) se puede usar para optimizar el rendimiento de los flujos de trabajo al dividir el trabajo entre múltiples procesos en una máquina determinada, aprovechando los múltiples núcleos de CPU disponibles en el hardware de la computadora moderna. . Identificaremos las operaciones de ráster candidatas que se benefician más del cómputo paralelo y aprenderemos a desarrollar sistemas paralelos eficientes para el geoprocesamiento de ráster dentro del entorno robusto de Python.
Las operaciones de ráster candidatas para la paralelización se pueden clasificar en general en tres escenarios de geoprocesamiento. El paralelismo se invoca utilizando un mecanismo diferente para cada escenario.
• Procesamiento de un dataset ráster grande con una única herramienta de análisis
• Procesamiento por lotes de una colección de datasets ráster ejecutando una sola herramienta de análisis varias veces
• Flujo de trabajo de geoprocesamiento de trama ejecutando herramientas de análisis adecuadas encadenadas
A partir de nuestras pruebas internas, evaluamos el rendimiento de una operación local ejecutada paralelamente en un gran conjunto de datos de muestra. El siguiente gráfico resume las mejoras de rendimiento que se observaron.
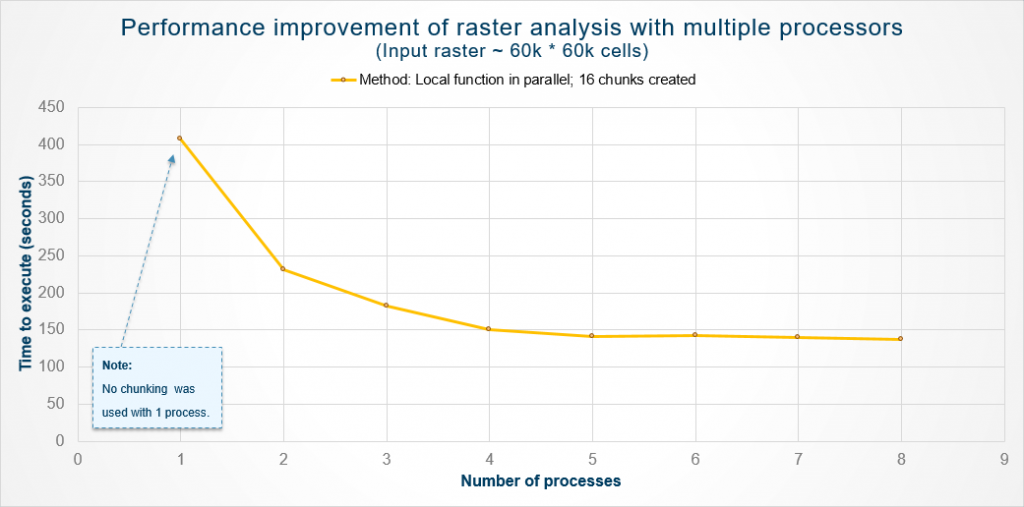
Las ventajas de optimizar las tareas de análisis de trama con multiproceso de Python son evidentes a partir de este gráfico. Podemos ver mejoras significativas al agregar más procesos para ayudar con el análisis, especialmente yendo de uno a cuatro procesos. Más allá de eso, las ganancias fueron insignificantes debido a la sobrecarga de engendrar múltiples procesos.
Procesamiento de un dataset de ráster grande
El aumento en la resolución de los datasets ráster ha llevado a tamaños de datos cada vez más grandes. Actualmente, los conjuntos de datos están en el orden de gigabytes y están aumentando, con miles de millones de celdas de trama. Mientras que el poder de cómputo de los procesadores y el tamaño de la memoria en las computadoras han aumentado apreciablemente, los equipos y algoritmos heredados adecuados para manipular pequeños rásteres con una resolución más gruesa hacen que el procesamiento de estas fuentes de datos mejorados sea costoso. [1]
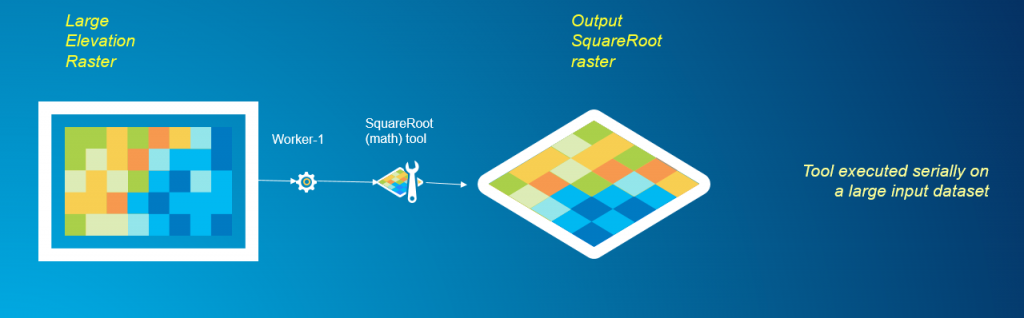
La descomposición de datos, también conocida como dividir y conquistar, es una estrategia popular utilizada en computación paralela que aprovecharemos para procesar paralelamente un gran conjunto de datos ráster. Los algoritmos utilizados en las herramientas de análisis de trama se pueden clasificar en general en cuatro categorías: operaciones locales, focales, zonales y globales. Para profundizar en los tipos de operaciones de ráster basadas en celdas, lea este artículo. Las operaciones de ráster local, focal y zonal son simples de programar cuando se trata de descomposición de datos. Una vez que los datos se descomponen de manera apropiada, cada fragmento de datos puede ser operado independientemente por un proceso sin la necesidad de comunicarse con otros procesos. Sin embargo, las operaciones globales de ráster son más difíciles de integrar con la descomposición de datos y requieren comunicación entre procesos. Veamos un ejemplo de procesamiento de un dataset de ráster grande utilizando una operación de ráster matemático local, Square Root. Las operaciones locales o por celda son las más simples para paralelizar utilizando una estrategia de 'dividir y conquistar', ya que el valor resultante en cada celda solo depende del valor de entrada en esa ubicación de celda. Para cada celda, la herramienta Square Root calcula la raíz cuadrada del valor de esa celda. Usar la herramienta en serie significa simplemente ejecutar la herramienta Square Root en todo el gran conjunto de datos, pero este proceso puede llevar mucho tiempo.
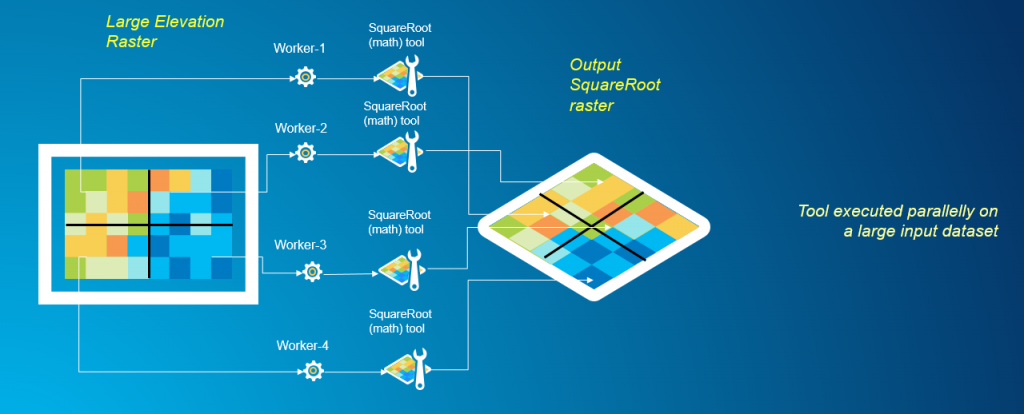
En cambio, a través de la descomposición de datos, podemos rediseñar la tarea de análisis para utilizar múltiples procesos de trabajo simultáneamente, mejorando así el rendimiento del análisis general. El siguiente gráfico muestra la división del dominio de un ráster grande en varios fragmentos más pequeños, y el uso de múltiples procesos de trabajo para realizar simultáneamente análisis en cada una de las subsecciones. Los resultados se vuelven a unir para el resultado final.
Aquí se comparte una secuencia de comandos de muestra en GitHub que profundiza sobre cómo este problema puede resolverse mediante programación utilizando ArcGIS Desktop y el módulo de multiprocesamiento de Python.
Procesamiento por lotes de una colección de datasets ráster
Cuando se trata de procesar por lotes muchos conjuntos de datos a través de una herramienta de análisis de trama, el enfoque común sería usar un iterador en ModelBuilder o escribir un script de Python con un ciclo para iterar sobre cada conjunto de datos en el lote y procesarlos en serie. Este método puede consumir mucho tiempo cuando se trabaja con una gran colección de rásteres, particularmente cuando se ejecutan tareas de análisis que tienen tiempos de cálculo significativos.
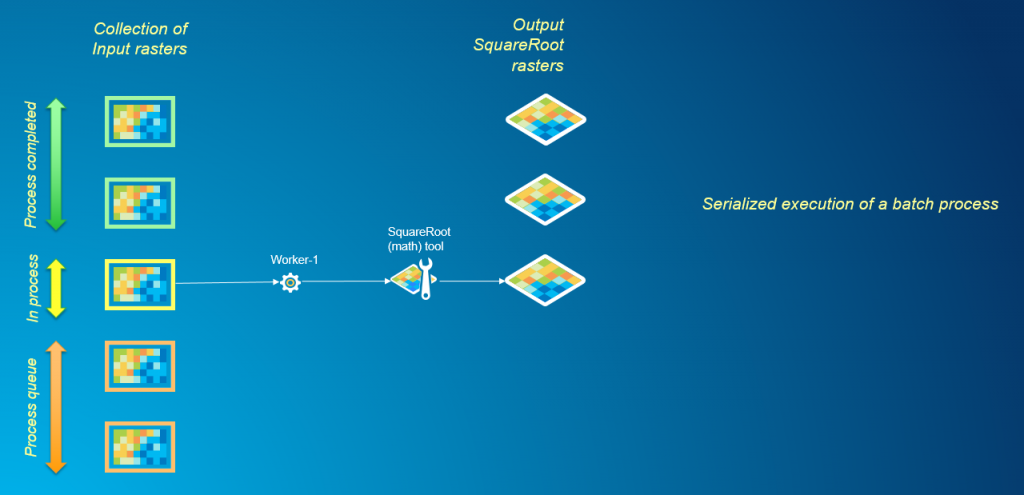
El paralelismo es un mecanismo directo para el procesamiento por lotes cuando el análisis de cada conjunto de datos en el lote se puede realizar de forma independiente del resto. En el siguiente gráfico, podemos ver cómo varios procesos que trabajan simultáneamente permiten un procesamiento más rápido de la cola de proceso por lotes.
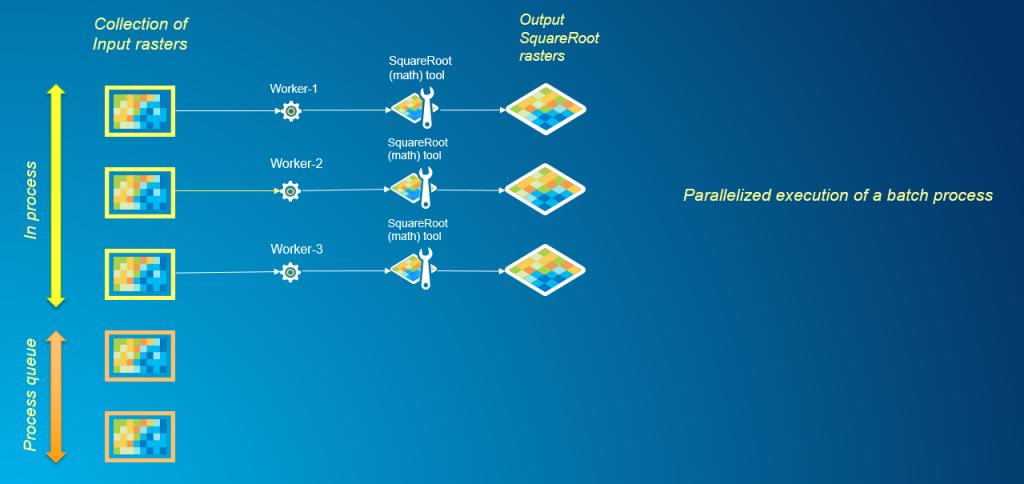
Aquí se comparte una secuencia de comandos de muestra en GitHub que describe en detalle cómo se puede resolver el procesamiento por lotes mediante programación utilizando ArcGIS Desktop y el módulo de multiprocesamiento de Python.
Flujos de trabajo de geoprocesamiento de trama
Un flujo de trabajo de geoprocesamiento es un procedimiento de varios pasos que combina herramientas de geoprocesamiento y datos geográficos para producir un resultado significativo. Dentro de ArcGIS, los flujos de trabajo de geoprocesamiento de trama se pueden escribir como modelos usando ModelBuilder o como scripts de Python. El enfoque estándar en ambos casos es encadenar las herramientas necesarias para realizar su análisis y ejecutarlas en serie. Veamos un ejemplo de flujo de trabajo que evalúa un ráster de idoneidad ejecutando las herramientas Pendiente, Aspecto, Reclasificar y Suma ponderada. Estas herramientas están disponibles como parte de Spatial Analyst Extension en ArcGIS Desktop.
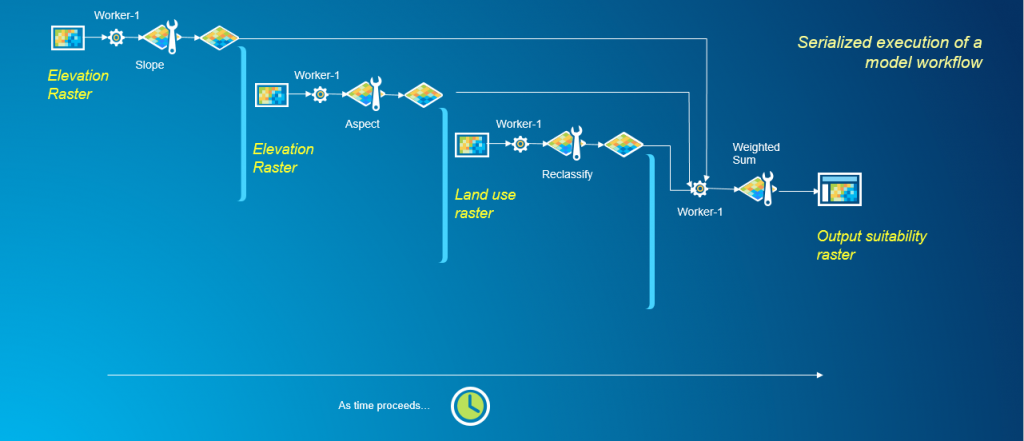
En el ejemplo anterior, como las herramientas se ejecutan en serie, solo se puede utilizar un proceso de trabajo a la vez para completar el flujo de trabajo. Para paralelizar cualquier flujo de trabajo de geoprocesamiento, la primera tarea es descomponer el problema e identificar partes de él que pueden manejarse de forma independiente. Este flujo de trabajo es un buen candidato para el procesamiento paralelo ya que la ejecución de las herramientas Slope, Aspect y Reclassify son tareas independientes. Estas tareas no tienen dependencias en la ejecución de otras herramientas en el flujo de trabajo. Sin embargo, la herramienta Suma ponderada es una tarea dependiente, que tiene dependencias en los resultados de las herramientas Pendiente, Aspecto y Reclasificar. Hasta que las herramientas Pendiente, Aspecto y Reclasificar no hayan terminado de ejecutarse, la herramienta Suma ponderada no puede comenzar su análisis. Habiendo identificado las tareas independientes y dependientes dentro de este flujo de trabajo, podemos rediseñar este problema para paralelizarlo.
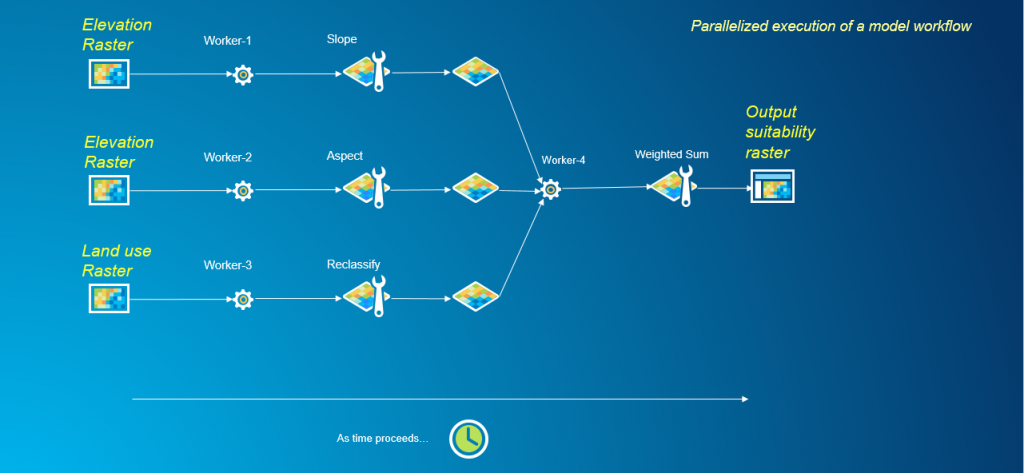
En este flujo de trabajo rediseñado, hacemos uso de múltiples procesos de trabajo para ejecutar tareas independientes simultáneamente, en lugar de depender de un solo trabajador para procesar cada tarea en serie.
Mejores prácticas y consideraciones
Hay muchos factores que se deben tener en cuenta al combinar las capacidades de los módulos arcpy y multiproceso para mejorar el rendimiento de las tareas de geoprocesamiento de trama.
• Siempre hay gastos generales asociados con el desove de múltiples procesos que deben tenerse en cuenta cuando se considera un enfoque paralelizado. En situaciones donde la tarea de procesamiento es compleja y los datos de procesamiento son grandes o el tamaño del lote es enorme, el paralelismo puede proporcionar beneficios de desempeño que superan la sobrecarga. En otras situaciones, como cuando la tarea de procesamiento es muy simple, o si los conjuntos de datos de procesamiento no fueron particularmente grandes, puede ser que utilizar multiprocesamiento no proporcione ningún beneficio de rendimiento significativo y, en algunos casos, ralentice la velocidad de procesamiento general. Como paralelizar su código puede ser tedioso, debe considerar el objetivo final y el costo de oportunidad de invertir tiempo en la paralelización. Para una tarea que se ejecuta de forma repetitiva, por ejemplo de forma planificada, y en el procesamiento de big data, la paralelización puede ser ventajosa.
• Evite escribir rásteres de salida desde múltiples procesos en una geodatabase de archivos (FGDB) común o en múltiples rásteres Esri Grid dentro de un espacio de trabajo de carpeta común. Estos formatos de salida a menudo experimentan bloqueos de esquema o problemas de sincronización cuando se accede por múltiples procesos simultáneos.
• Se recomienda usar ArcGIS Pro, ArcGIS Server o ArcMap con ArcGIS for Desktop Background Geoprocessing (64 bits) para el análisis de ráster paralelizado. Usar el procesamiento de 64 bits para realizar análisis en sistemas con grandes cantidades de RAM puede ayudar a procesar datos de gran tamaño de manera eficiente.
Referencias
[1] Barnes, Lehman, Mulla. "Diluvio de prioridad: un algoritmo óptimo para el llenado de la depresión y el etiquetado de cuencas hidrográficas para modelos de elevación digital". Computadoras y Geociencias. Vol 62, enero de 2014, páginas 117-127, doi: "10.1016 / j.cageo.2013.04.024Lea el artículo original | Para más información sobre el multiproceso con ArcGIS, ¡escríbanos! un ejecutivo de SIGSA lo está esperando | Visítenos www.sigsa.info
Con el crecimiento de los tamaños de datos de ráster, los tiempos de procesamiento para el análisis son cada vez más largos. Sin embargo, al emplear conceptos de computación en paralelo, podemos mejorar el rendimiento y la escalabilidad de los flujos de trabajo con las herramientas de Spatial Analyst. En este blog, identificaremos escenarios donde el módulo de multiprocesamiento Python (Python.org) se puede usar para optimizar el rendimiento de los flujos de trabajo al dividir el trabajo entre múltiples procesos en una máquina determinada, aprovechando los múltiples núcleos de CPU disponibles en el hardware de la computadora moderna. . Identificaremos las operaciones de ráster candidatas que se benefician más del cómputo paralelo y aprenderemos a desarrollar sistemas paralelos eficientes para el geoprocesamiento de ráster dentro del entorno robusto de Python.
Las operaciones de ráster candidatas para la paralelización se pueden clasificar en general en tres escenarios de geoprocesamiento. El paralelismo se invoca utilizando un mecanismo diferente para cada escenario.
• Procesamiento de un dataset ráster grande con una única herramienta de análisis
• Procesamiento por lotes de una colección de datasets ráster ejecutando una sola herramienta de análisis varias veces
• Flujo de trabajo de geoprocesamiento de trama ejecutando herramientas de análisis adecuadas encadenadas
A partir de nuestras pruebas internas, evaluamos el rendimiento de una operación local ejecutada paralelamente en un gran conjunto de datos de muestra. El siguiente gráfico resume las mejoras de rendimiento que se observaron.
Las ventajas de optimizar las tareas de análisis de trama con multiproceso de Python son evidentes a partir de este gráfico. Podemos ver mejoras significativas al agregar más procesos para ayudar con el análisis, especialmente yendo de uno a cuatro procesos. Más allá de eso, las ganancias fueron insignificantes debido a la sobrecarga de engendrar múltiples procesos.
Procesamiento de un dataset de ráster grande
El aumento en la resolución de los datasets ráster ha llevado a tamaños de datos cada vez más grandes. Actualmente, los conjuntos de datos están en el orden de gigabytes y están aumentando, con miles de millones de celdas de trama. Mientras que el poder de cómputo de los procesadores y el tamaño de la memoria en las computadoras han aumentado apreciablemente, los equipos y algoritmos heredados adecuados para manipular pequeños rásteres con una resolución más gruesa hacen que el procesamiento de estas fuentes de datos mejorados sea costoso. [1]
La descomposición de datos, también conocida como dividir y conquistar, es una estrategia popular utilizada en computación paralela que aprovecharemos para procesar paralelamente un gran conjunto de datos ráster. Los algoritmos utilizados en las herramientas de análisis de trama se pueden clasificar en general en cuatro categorías: operaciones locales, focales, zonales y globales. Para profundizar en los tipos de operaciones de ráster basadas en celdas, lea este artículo. Las operaciones de ráster local, focal y zonal son simples de programar cuando se trata de descomposición de datos. Una vez que los datos se descomponen de manera apropiada, cada fragmento de datos puede ser operado independientemente por un proceso sin la necesidad de comunicarse con otros procesos. Sin embargo, las operaciones globales de ráster son más difíciles de integrar con la descomposición de datos y requieren comunicación entre procesos. Veamos un ejemplo de procesamiento de un dataset de ráster grande utilizando una operación de ráster matemático local, Square Root. Las operaciones locales o por celda son las más simples para paralelizar utilizando una estrategia de 'dividir y conquistar', ya que el valor resultante en cada celda solo depende del valor de entrada en esa ubicación de celda. Para cada celda, la herramienta Square Root calcula la raíz cuadrada del valor de esa celda. Usar la herramienta en serie significa simplemente ejecutar la herramienta Square Root en todo el gran conjunto de datos, pero este proceso puede llevar mucho tiempo.
En cambio, a través de la descomposición de datos, podemos rediseñar la tarea de análisis para utilizar múltiples procesos de trabajo simultáneamente, mejorando así el rendimiento del análisis general. El siguiente gráfico muestra la división del dominio de un ráster grande en varios fragmentos más pequeños, y el uso de múltiples procesos de trabajo para realizar simultáneamente análisis en cada una de las subsecciones. Los resultados se vuelven a unir para el resultado final.
Aquí se comparte una secuencia de comandos de muestra en GitHub que profundiza sobre cómo este problema puede resolverse mediante programación utilizando ArcGIS Desktop y el módulo de multiprocesamiento de Python.
Procesamiento por lotes de una colección de datasets ráster
Cuando se trata de procesar por lotes muchos conjuntos de datos a través de una herramienta de análisis de trama, el enfoque común sería usar un iterador en ModelBuilder o escribir un script de Python con un ciclo para iterar sobre cada conjunto de datos en el lote y procesarlos en serie. Este método puede consumir mucho tiempo cuando se trabaja con una gran colección de rásteres, particularmente cuando se ejecutan tareas de análisis que tienen tiempos de cálculo significativos.
El paralelismo es un mecanismo directo para el procesamiento por lotes cuando el análisis de cada conjunto de datos en el lote se puede realizar de forma independiente del resto. En el siguiente gráfico, podemos ver cómo varios procesos que trabajan simultáneamente permiten un procesamiento más rápido de la cola de proceso por lotes.
Aquí se comparte una secuencia de comandos de muestra en GitHub que describe en detalle cómo se puede resolver el procesamiento por lotes mediante programación utilizando ArcGIS Desktop y el módulo de multiprocesamiento de Python.
Flujos de trabajo de geoprocesamiento de trama
Un flujo de trabajo de geoprocesamiento es un procedimiento de varios pasos que combina herramientas de geoprocesamiento y datos geográficos para producir un resultado significativo. Dentro de ArcGIS, los flujos de trabajo de geoprocesamiento de trama se pueden escribir como modelos usando ModelBuilder o como scripts de Python. El enfoque estándar en ambos casos es encadenar las herramientas necesarias para realizar su análisis y ejecutarlas en serie. Veamos un ejemplo de flujo de trabajo que evalúa un ráster de idoneidad ejecutando las herramientas Pendiente, Aspecto, Reclasificar y Suma ponderada. Estas herramientas están disponibles como parte de Spatial Analyst Extension en ArcGIS Desktop.
En el ejemplo anterior, como las herramientas se ejecutan en serie, solo se puede utilizar un proceso de trabajo a la vez para completar el flujo de trabajo. Para paralelizar cualquier flujo de trabajo de geoprocesamiento, la primera tarea es descomponer el problema e identificar partes de él que pueden manejarse de forma independiente. Este flujo de trabajo es un buen candidato para el procesamiento paralelo ya que la ejecución de las herramientas Slope, Aspect y Reclassify son tareas independientes. Estas tareas no tienen dependencias en la ejecución de otras herramientas en el flujo de trabajo. Sin embargo, la herramienta Suma ponderada es una tarea dependiente, que tiene dependencias en los resultados de las herramientas Pendiente, Aspecto y Reclasificar. Hasta que las herramientas Pendiente, Aspecto y Reclasificar no hayan terminado de ejecutarse, la herramienta Suma ponderada no puede comenzar su análisis. Habiendo identificado las tareas independientes y dependientes dentro de este flujo de trabajo, podemos rediseñar este problema para paralelizarlo.
En este flujo de trabajo rediseñado, hacemos uso de múltiples procesos de trabajo para ejecutar tareas independientes simultáneamente, en lugar de depender de un solo trabajador para procesar cada tarea en serie.
Mejores prácticas y consideraciones
Hay muchos factores que se deben tener en cuenta al combinar las capacidades de los módulos arcpy y multiproceso para mejorar el rendimiento de las tareas de geoprocesamiento de trama.
• Siempre hay gastos generales asociados con el desove de múltiples procesos que deben tenerse en cuenta cuando se considera un enfoque paralelizado. En situaciones donde la tarea de procesamiento es compleja y los datos de procesamiento son grandes o el tamaño del lote es enorme, el paralelismo puede proporcionar beneficios de desempeño que superan la sobrecarga. En otras situaciones, como cuando la tarea de procesamiento es muy simple, o si los conjuntos de datos de procesamiento no fueron particularmente grandes, puede ser que utilizar multiprocesamiento no proporcione ningún beneficio de rendimiento significativo y, en algunos casos, ralentice la velocidad de procesamiento general. Como paralelizar su código puede ser tedioso, debe considerar el objetivo final y el costo de oportunidad de invertir tiempo en la paralelización. Para una tarea que se ejecuta de forma repetitiva, por ejemplo de forma planificada, y en el procesamiento de big data, la paralelización puede ser ventajosa.
• Evite escribir rásteres de salida desde múltiples procesos en una geodatabase de archivos (FGDB) común o en múltiples rásteres Esri Grid dentro de un espacio de trabajo de carpeta común. Estos formatos de salida a menudo experimentan bloqueos de esquema o problemas de sincronización cuando se accede por múltiples procesos simultáneos.
• Se recomienda usar ArcGIS Pro, ArcGIS Server o ArcMap con ArcGIS for Desktop Background Geoprocessing (64 bits) para el análisis de ráster paralelizado. Usar el procesamiento de 64 bits para realizar análisis en sistemas con grandes cantidades de RAM puede ayudar a procesar datos de gran tamaño de manera eficiente.
Referencias
[1] Barnes, Lehman, Mulla. "Diluvio de prioridad: un algoritmo óptimo para el llenado de la depresión y el etiquetado de cuencas hidrográficas para modelos de elevación digital". Computadoras y Geociencias. Vol 62, enero de 2014, páginas 117-127, doi: "10.1016 / j.cageo.2013.04.024Lea el artículo original | Para más información sobre el multiproceso con ArcGIS, ¡escríbanos! un ejecutivo de SIGSA lo está esperando | Visítenos www.sigsa.info



Comentarios
Publicar un comentario