Amplíe su análisis de Big Data con GeoAnalytics Server y Spark
Amplíe
su análisis de Big Data con GeoAnalytics Server y Spark
Por
Noah Slocum
ArcGIS GeoAnalytics Server viene con 25 herramientas
en 10.7, pero ¿qué sucede si desea ejecutar un análisis distribuido y la
herramienta que necesita no está disponible? Con esta versión, en el equipo de
GeoAnalytics nos complace anunciar una nueva forma de administrar y analizar
sus grandes conjuntos de datos utilizando una herramienta llamada Run Python Script.
Como
puede suponer, Run Python Script ejecuta código en un entorno Python en su
servidor GeoAnalytics. Entonces, ¿de qué se trata la emoción? Este entorno de
Python le da acceso a Apache Spark, el motor que distribuye datos y
análisis a través de los núcleos de cada máquina en un sitio de GeoAnalytics
Server. Con Spark puede personalizar su análisis y ampliar sus capacidades de
análisis mediante:
·
Consulta y resumen de sus datos usando SQL
·
Convertir los flujos de trabajo de análisis en tuberías
de herramientas de GeoAnalytics
·
Clasificar, agrupar o modelar datos no espaciales con las
bibliotecas de aprendizaje automático incluidas
¡Todo
utilizando el poder de la computación distribuida! Al igual que otras herramientas
de GeoAnalytics, esto significa que puede encontrar respuestas en sus grandes
conjuntos de datos mucho más rápido que otras herramientas no distribuidas.
La
API de pyspark proporciona una interfaz
para trabajar con Spark, y en esta publicación de blog nos gustaría mostrarle
lo fácil que es comenzar con pyspark y comenzar a aprovechar todo lo que tiene
para ofrecer.
Explore
y administre capas de ArcGIS Enterprise como DataFrames
Cuando
se usa la API pyspark, los datos a menudo se representan como Spark DataFrames. Si está familiarizado
con Pandas o R DataFrames, la versión de Spark es conceptualmente similar, pero
optimizada para el procesamiento de datos distribuidos.
Cuando
realiza una operación en un DataFrame (como ejecutar una consulta SQL), los
datos de origen se distribuirán en los núcleos del sitio del servidor, lo que
significa que puede trabajar con grandes conjuntos de datos mucho más rápido
que con un enfoque no distribuido.
Run
Python Script incluye soporte integrado para cargar capas de ArcGIS Enterprise
en Spark DataFrames, lo que significa que puede crear un DataFrame desde un
servicio de entidades o compartir archivos de grandes datos con una línea de
código.
df =
spark.read.format ("webgis"). load ()
Las
operaciones de DataFrame se pueden llamar para consultar la capa, actualizar el
esquema, resumir columnas y más. La información de geometría y tiempo se
conservará en campos llamados $ geometry y $ time, por lo que puede usarlos como
cualquier otra columna.
Cuando
esté listo para volver a escribir una capa en ArcGIS Enterprise, todo lo que
necesita es:
df.write.format
("webgis"). save ()
y
la capa de resultados estará disponible como un servicio de características o
un archivo compartido de big data en su Portal. La API de pyspark también
admite la escritura en muchos tipos de ubicaciones externas a ArcGIS
Enterprise, lo que permite la conexión de GeoAnalytics a otras soluciones de
big data.
Cree
canales de análisis con las herramientas de GeoAnalytics
El
entorno Run Python Script Python viene con un módulo de geoanálisis que expone la mayoría de
las herramientas de GeoAnalytics como métodos pyspark. Estos métodos aceptan
DataFrames como capas de entrada y también devuelven resultados como
DataFrames, pero no se escribe nada en un almacén de datos hasta que llame a
write () en el DataFrame.
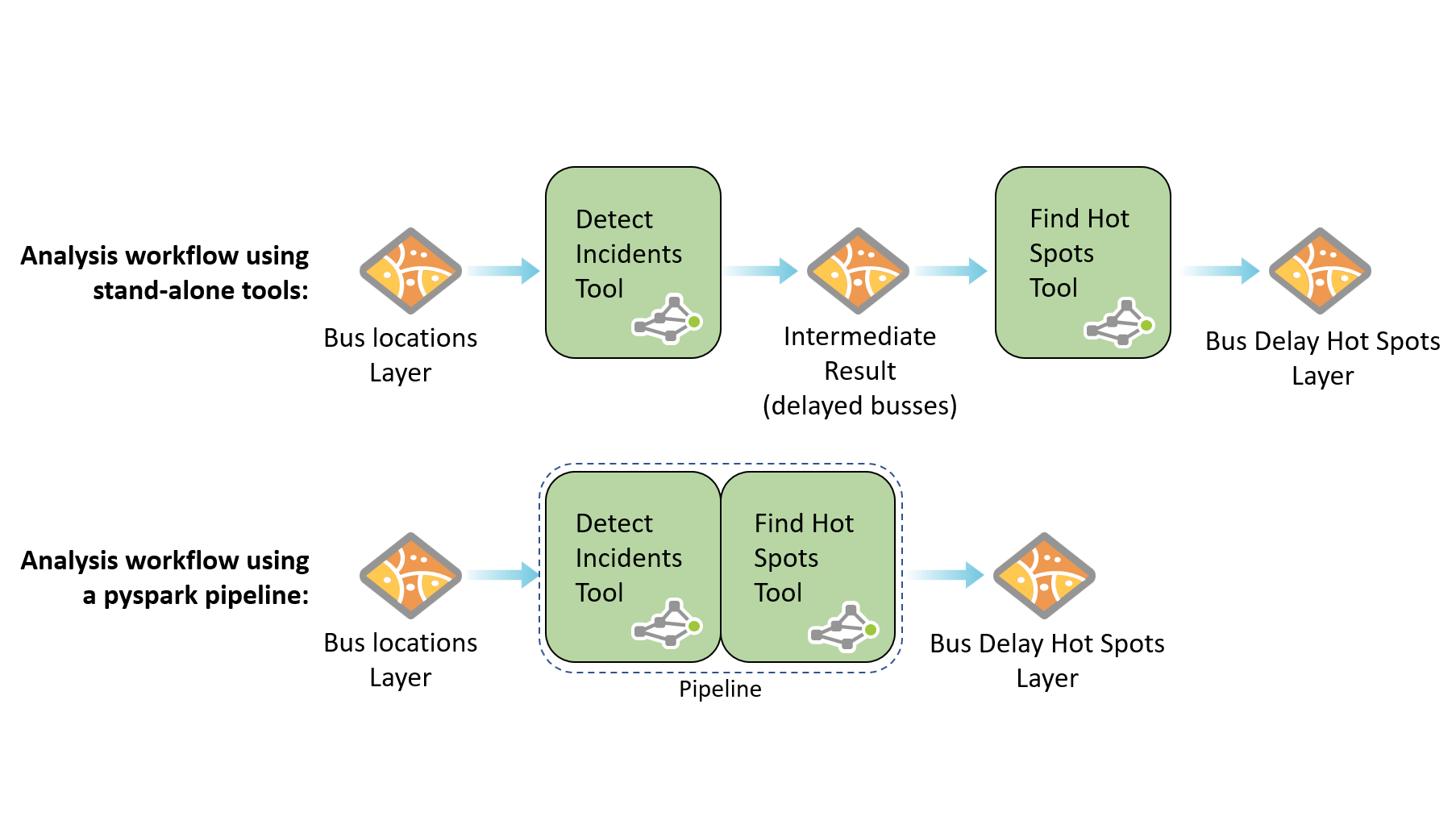
Esto
significa que puede encadenar múltiples herramientas de GeoAnalytics en una tubería, lo que reduce el tiempo
de procesamiento general y evita crear capas intermedias innecesarias en su
almacén de datos. Al trabajar con grandes conjuntos de datos, estos resultados
intermedios podrían ascender a 100 GB de datos, ¡pero no con pyspark!
Consulte
este script de ejemplo que encadena varias herramientas
de GeoAnalytics en una sola tubería de análisis.
Aproveche
las herramientas distribuidas de aprendizaje automático con pyspark.mllib
Mientras
que el módulo de geoanálisis ofrece potentes herramientas de análisis espacial,
el paquete pyspark.mllib incluye docenas de
herramientas distribuidas no espaciales para clasificación, predicción,
agrupación y más.
Ahora
que el paquete pyspark.mllib está expuesto, puede crear un clasificador Naïve Bayes, realizar clustering
multivariado con k-means o construir un modelo de regresión
isotónica,
todo utilizando los recursos en su sitio de GeoAnalytics Server.
Estas
herramientas de entrada y salida de DataFrames, lo que significa que puede
encadenarlas con las herramientas de GeoAnalytics y entre sí para crear
tuberías. Si bien pyspark.mllib no tiene soporte nativo para datos espaciales,
puede usar GeoAnalytics para calcular representaciones tabulares de datos
espaciales y usar eso con pyspark.mllib.
Por
ejemplo, podría crear una cuadrícula de múltiples variables con GeoAnalytics y usar
variables (como la distancia a la característica más cercana o el atributo de
la característica más cercana) como datos de entrenamiento en una máquina de vectores de
soporte,
un método no disponible como herramienta GeoAnalytics pero expuesto en el mllib
paquete.
Resumen
Estamos
entusiasmados de ver qué hace con esta nueva forma de interrogar y analizar sus
datos de gran tamaño con GeoAnalytics Server. Además de los ejemplos vinculados
anteriormente, asegúrese de consultar esta página de GitHub que hice con más ejemplos
y una utilidad para ejecutar la
herramienta Ejecutar script Python a través de la línea de comandos o
Python.
SOBRE
EL AUTOR
Noah Slocum
Soy
ingeniero de producto en el equipo de GeoAnalytics en Esri en Redlands, CA



Comentarios
Publicar un comentario